

Practice Dna Structure And Replication
Biologists in the 1940s had difficulty in accepting Dna equally the genetic material because of the credible simplicity of its chemistry. Dna was known to be a long polymer composed of only four types of subunits, which resemble 1 another chemically. Early in the 1950s, DNA was offset examined past 10-ray diffraction analysis, a technique for determining the three-dimensional diminutive structure of a molecule (discussed in Affiliate viii). The early on x-ray diffraction results indicated that Dna was equanimous of 2 strands of the polymer wound into a helix. The observation that DNA was double-stranded was of crucial significance and provided one of the major clues that led to the Watson-Crick structure of Dna. Only when this model was proposed did DNA'due south potential for replication and information encoding go credible. In this department we examine the structure of the DNA molecule and explain in general terms how it is able to store hereditary information.
A Dna Molecule Consists of 2 Complementary Chains of Nucleotides
A Dna molecule consists of 2 long polynucleotide chains equanimous of iv types of nucleotide subunits. Each of these bondage is known as a Deoxyribonucleic acid chain, or a DNA strand. Hydrogen bonds between the base portions of the nucleotides concur the two bondage together (Effigy 4-3). Every bit nosotros saw in Chapter 2 (Panel 2-6, pp. 120-121), nucleotides are composed of a five-carbon saccharide to which are attached one or more than phosphate groups and a nitrogen-containing base of operations. In the example of the nucleotides in DNA, the sugar is deoxyribose fastened to a single phosphate grouping (hence the name deoxyribonucleic acid), and the base may be either adenine (A), cytosine (C), guanine (G), or thymine (T). The nucleotides are covalently linked together in a chain through the sugars and phosphates, which thus form a "courage" of alternating carbohydrate-phosphate-saccharide-phosphate (run across Figure 4-iii). Considering only the base differs in each of the four types of subunits, each polynucleotide chain in Deoxyribonucleic acid is analogous to a necklace (the backbone) strung with four types of beads (the four bases A, C, Grand, and T). These same symbols (A, C, Chiliad, and T) are also commonly used to denote the four different nucleotides—that is, the bases with their fastened sugar and phosphate groups.
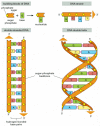
Effigy 4-3
Deoxyribonucleic acid and its building blocks. Dna is made of 4 types of nucleotides, which are linked covalently into a polynucleotide chain (a Dna strand) with a sugar-phosphate backbone from which the bases (A, C, Yard, and T) extend. A Deoxyribonucleic acid molecule is composed of ii (more than...)
The way in which the nucleotide subunits are lined together gives a Dna strand a chemical polarity. If we think of each sugar as a cake with a protruding knob (the five′ phosphate) on 1 side and a hole (the 3′ hydroxyl) on the other (run across Figure 4-three), each completed chain, formed by interlocking knobs with holes, will have all of its subunits lined upward in the aforementioned orientation. Moreover, the two ends of the concatenation will be easily distinguishable, as ane has a hole (the iii′ hydroxyl) and the other a knob (the 5′ phosphate) at its terminus. This polarity in a DNA chain is indicated past referring to one stop as the 3′ cease and the other as the 5′ end.
The three-dimensional structure of DNA—the double helix—arises from the chemical and structural features of its 2 polynucleotide chains. Because these two chains are held together by hydrogen bonding between the bases on the different strands, all the bases are on the inside of the double helix, and the sugar-phosphate backbones are on the exterior (see Figure 4-iii). In each case, a bulkier ii-band base (a purine; run across Panel 2-half-dozen, pp. 120–121) is paired with a single-ring base of operations (a pyrimidine); A ever pairs with T, and 1000 with C (Effigy 4-iv). This complementary base-pairing enables the base pairs to be packed in the energetically about favorable arrangement in the interior of the double helix. In this arrangement, each base of operations pair is of similar width, thus holding the sugar-phosphate backbones an equal distance apart along the DNA molecule. To maximize the efficiency of base-pair packing, the two carbohydrate-phosphate backbones current of air around each other to form a double helix, with one complete turn every ten base pairs (Figure 4-5).

Figure 4-4
Complementary base pairs in the Deoxyribonucleic acid double helix. The shapes and chemical construction of the bases let hydrogen bonds to form efficiently but between A and T and between Grand and C, where atoms that are able to form hydrogen bonds (come across Panel 2-iii, pp. 114–115) (more...)

Figure iv-v
The Dna double helix. (A) A space-filling model of 1.5 turns of the DNA double helix. Each turn of DNA is made upward of ten.4 nucleotide pairs and the heart-to-center altitude between next nucleotide pairs is three.iv nm. The coiling of the two strands effectually (more...)
The members of each base of operations pair tin fit together inside the double helix only if the two strands of the helix are antiparallel—that is, only if the polarity of i strand is oriented reverse to that of the other strand (encounter Figures four-iii and iv-iv). A consequence of these base-pairing requirements is that each strand of a Dna molecule contains a sequence of nucleotides that is exactly complementary to the nucleotide sequence of its partner strand.
The Structure of DNA Provides a Mechanism for Heredity
Genes carry biological data that must be copied accurately for transmission to the next generation each time a cell divides to class ii girl cells. 2 central biological questions arise from these requirements: how can the information for specifying an organism exist carried in chemical form, and how is information technology accurately copied? The discovery of the structure of the DNA double helix was a landmark in twentieth-century biology considering information technology immediately suggested answers to both questions, thereby resolving at the molecular level the trouble of heredity. We talk over briefly the answers to these questions in this section, and nosotros shall examine them in more detail in subsequent chapters.
Dna encodes information through the social club, or sequence, of the nucleotides along each strand. Each base—A, C, T, or 1000—can be considered equally a letter in a iv-letter of the alphabet alphabet that spells out biological letters in the chemic structure of the DNA. As nosotros saw in Affiliate 1, organisms differ from 1 another because their corresponding Deoxyribonucleic acid molecules accept different nucleotide sequences and, consequently, carry different biological letters. Only how is the nucleotide alphabet used to make messages, and what do they spell out?
Equally discussed to a higher place, it was known well earlier the structure of Dna was determined that genes contain the instructions for producing proteins. The DNA messages must therefore somehow encode proteins (Figure iv-6). This human relationship immediately makes the problem easier to understand, considering of the chemical grapheme of proteins. As discussed in Affiliate 3, the properties of a protein, which are responsible for its biological function, are determined by its three-dimensional structure, and its structure is determined in turn by the linear sequence of the amino acids of which it is composed. The linear sequence of nucleotides in a gene must therefore somehow spell out the linear sequence of amino acids in a protein. The exact correspondence betwixt the four-letter nucleotide alphabet of Dna and the twenty-letter amino acrid alphabet of proteins—the genetic code—is not obvious from the DNA construction, and information technology took over a decade afterwards the discovery of the double helix earlier it was worked out. In Chapter 6 nosotros describe this code in detail in the class of elaborating the process, known as factor expression, through which a cell translates the nucleotide sequence of a gene into the amino acid sequence of a protein.

Figure 4-6
The relationship between genetic information carried in DNA and proteins.
The complete set up of information in an organism's Deoxyribonucleic acid is called its genome, and it carries the information for all the proteins the organism will ever synthesize. (The term genome is also used to describe the Dna that carries this data.) The corporeality of information contained in genomes is staggering: for example, a typical homo prison cell contains 2 meters of DNA. Written out in the four-letter nucleotide alphabet, the nucleotide sequence of a very small human gene occupies a quarter of a page of text (Figure four-seven), while the complete sequence of nucleotides in the human being genome would fill more than a 1000 books the size of this one. In addition to other critical data, it carries the instructions for about xxx,000 distinct proteins.

Figure 4-seven
The nucleotide sequence of the human β-globin gene. This gene carries the information for the amino acid sequence of 1 of the 2 types of subunits of the hemoglobin molecule, which carries oxygen in the claret. A different gene, the α-globin (more...)
At each prison cell partition, the cell must re-create its genome to pass information technology to both daughter cells. The discovery of the structure of DNA as well revealed the principle that makes this copying possible: because each strand of DNA contains a sequence of nucleotides that is exactly complementary to the nucleotide sequence of its partner strand, each strand can act equally a template, or mold, for the synthesis of a new complementary strand. In other words, if we designate the two Deoxyribonucleic acid strands as S and S′, strand Due south can serve as a template for making a new strand S′, while strand S′ can serve every bit a template for making a new strand S (Figure 4-8). Thus, the genetic information in Deoxyribonucleic acid can be accurately copied by the beautifully uncomplicated process in which strand S separates from strand South′, and each separated strand so serves equally a template for the production of a new complementary partner strand that is identical to its former partner.
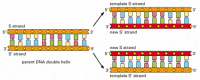
Figure 4-viii
DNA as a template for its own duplication. Equally the nucleotide A successfully pairs only with T, and G with C, each strand of DNA can specify the sequence of nucleotides in its complementary strand. In this manner, double-helical DNA can be copied precisely. (more...)
The ability of each strand of a Dna molecule to human activity every bit a template for producing a complementary strand enables a prison cell to re-create, or replicate, its genes before passing them on to its descendants. In the adjacent chapter we depict the elegant machinery the prison cell uses to perform this enormous job.
In Eucaryotes, Deoxyribonucleic acid Is Enclosed in a Prison cell Nucleus
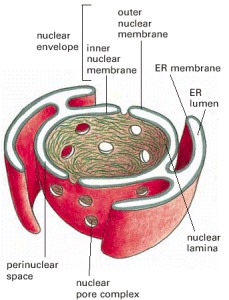
Nearly all the Dna in a eucaryotic cell is sequestered in a nucleus, which occupies nearly 10% of the total cell book. This compartment is delimited past a nuclear envelope formed by 2 concentric lipid bilayer membranes that are punctured at intervals by big nuclear pores, which transport molecules between the nucleus and the cytosol. The nuclear envelope is direct continued to the extensive membranes of the endoplasmic reticulum. It is mechanically supported past two networks of intermediate filaments: 1, called the nuclear lamina, forms a thin sheetlike meshwork inside the nucleus, merely beneath the inner nuclear membrane; the other surrounds the outer nuclear membrane and is less regularly organized (Effigy 4-9).
Figure 4-9
A cross-sectional view of a typical jail cell nucleus. The nuclear envelope consists of two membranes, the outer one being continuous with the endoplasmic reticulum membrane (see also Figure 12-9). The space inside the endoplasmic reticulum (the ER lumen) (more...)
The nuclear envelope allows the many proteins that act on DNA to be concentrated where they are needed in the cell, and, as we see in subsequent capacity, it also keeps nuclear and cytosolic enzymes separate, a feature that is crucial for the proper functioning of eucaryotic cells. Compartmentalization, of which the nucleus is an example, is an important principle of biology; information technology serves to constitute an surround in which biochemical reactions are facilitated past the high concentration of both substrates and the enzymes that act on them.
Summary
Genetic information is carried in the linear sequence of nucleotides in Dna. Each molecule of Deoxyribonucleic acid is a double helix formed from ii complementary strands of nucleotides held together by hydrogen bonds between Chiliad-C and A-T base pairs. Duplication of the genetic information occurs by the use of ane Dna strand as a template for formation of a complementary strand. The genetic information stored in an organism'south DNA contains the instructions for all the proteins the organism will ever synthesize. In eucaryotes, Dna is independent in the cell nucleus.

Practice Dna Structure And Replication,
Source: https://www.ncbi.nlm.nih.gov/books/NBK26821/
Posted by: garcialadiandal.blogspot.com
0 Response to "Practice Dna Structure And Replication"
Post a Comment